Abstract: End-to-end architectures are moving from research papers to mass production, yet the cornerstone of global autonomous driving safety evaluation — scenario-based development and testing — still rests on the assumption that systems can be decomposed into perception, planning, and control modules. This article systematically analyzes five structural challenges that scenario methods face in the end-to-end era, argues that they remain valid but are no longer sufficient, and proposes an evolutionary path that supplements scenario methods with large-scale aerial naturalistic driving data within a three-layer collaborative framework.

Figure 1
Prologue: A Paradigm Conflict in Progress
In 2024, a shift occurred in the autonomous driving industry that most safety engineers overlooked — yet it may fundamentally change how they work:
End-to-end architectures began moving from papers to production.
Tesla’s FSD V12 fully transitioned to an end-to-end neural network. Huawei, Li Auto, XPeng, and NIO successively released or announced their own end-to-end solutions. In academia, UniAD won the CVPR 2023 Best Paper award, DriveTransformer was featured at ICLR 2025, and DiffusionDrive became a CVPR 2025 Highlight.
Meanwhile, the cornerstone of global autonomous driving safety evaluation — scenario-based development and testing — still rests on a core assumption: that autonomous driving systems can be decomposed into perception, planning, and control modules, with disturbance factors identified separately for each, and test scenarios constructed accordingly.
When end-to-end merges these three modules into one, does this approach still work?
This is not an academic question. It is a practical issue that every SOTIF engineer, test engineer, and safety architect working on L2+/L3 products must confront today.
Figure 1: Article navigation map

Figure 2
1. Understanding the Technical Core of Scenario Methods
Before asking “is it still valid?”, we must first understand what scenario-based methods actually do. Many people’s understanding stops at “just listing a bunch of test scenarios” — that barely scratches the surface.
1.1 ISO 34502: Three Layers of Scenario Abstraction
ISO 34502:2022 is the most important international standard in scenario-based safety evaluation. It was led by Satoshi Taniguchi (Toyota), chair of the Japanese SAKURA project. It defines a three-layer scenario abstraction model:
The value of this three-layer model lies in this: it transforms “infinitely many driving situations” into a “finite and manageable scenario space.” Functional scenarios support expert discussions, logical scenarios enable parameterized test design, and concrete scenarios provide reproducible simulation tests.
Figure 2: ISO 34502 three-layer scenario abstraction model

Figure 3
1.2 SAKURA: Deriving Scenarios from Physical Principles
The previous article introduced the SAKURA framework in detail. Here, we focus on its most essential methodology — the Physical Principles Approach.
SAKURA decomposes the Dynamic Driving Task (DDT) into three processes, then systematically identifies disturbance factors for each based on physical principles:
Perception Process → Sensor physics disturbances ├── Camera: visible light properties → glare, reflection, low illumination ├── Millimeter-wave radar: EM wave properties → multipath reflection, mutual interference └── LiDAR: infrared light properties → rain/snow absorption, dust scattering
Planning Process → Traffic disturbances ├── Road geometry × ego vehicle behavior × surrounding vehicle behavior └── 24 highway scenarios + 58 vehicle traffic patterns + 8 VRU patterns
Control Process → Vehicle dynamics disturbances ├── Road surface conditions (slippery, standing water, ice/snow) ├── Wind forces (crosswind, gusts) └── Tire performance degradation
Figure 3: Driving tasks and disturbance factors
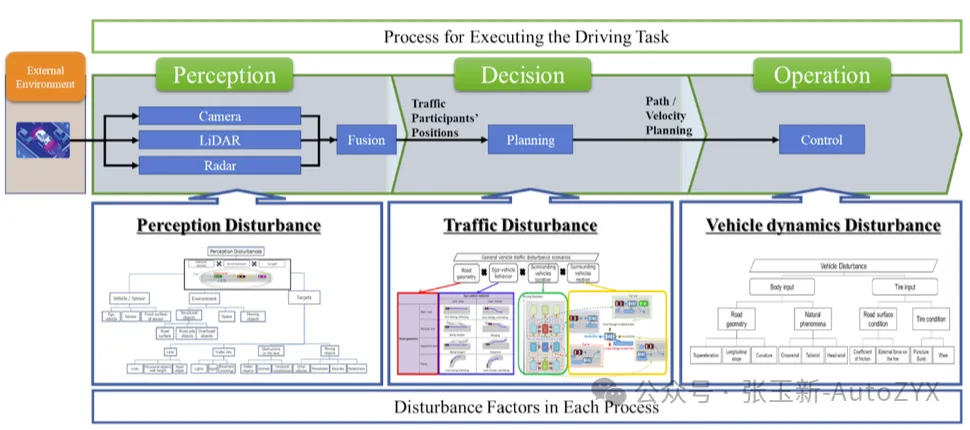
Figure 4
The core strength of this approach is that it does not rely on crash data (data-driven), but derives scenarios from first principles of physics (principles-driven). This makes it possible to argue for the completeness of the scenario set — you can explain “why these scenarios are sufficient.”
1.3 The Scale of Scenarios
Specifically, ISO 34502 defines 24 traffic disturbance scenarios for highways, generated through systematic combination of the following dimensions:
3 × 2 × 4 = 24 functional scenarios.
SAKURA V4.0 substantially expands on this: 58 vehicle traffic disturbance patterns + 8 VRU patterns, covering the complete scenario space for highways, urban roads, and vulnerable road users. V4.0 also adds urban driving scenarios and occlusion scenarios.
Within this framework, every scenario has a clear physical basis, and every parameter has a traceable origin.
This is currently the most systematic and rigorous scenario-based safety evaluation methodology in the world.
2. Five Structural Challenges in the End-to-End Era
Having fully understood scenario methods, let us examine the impact that end-to-end architectures bring.
Figure 4: Modular vs. end-to-end architecture comparison
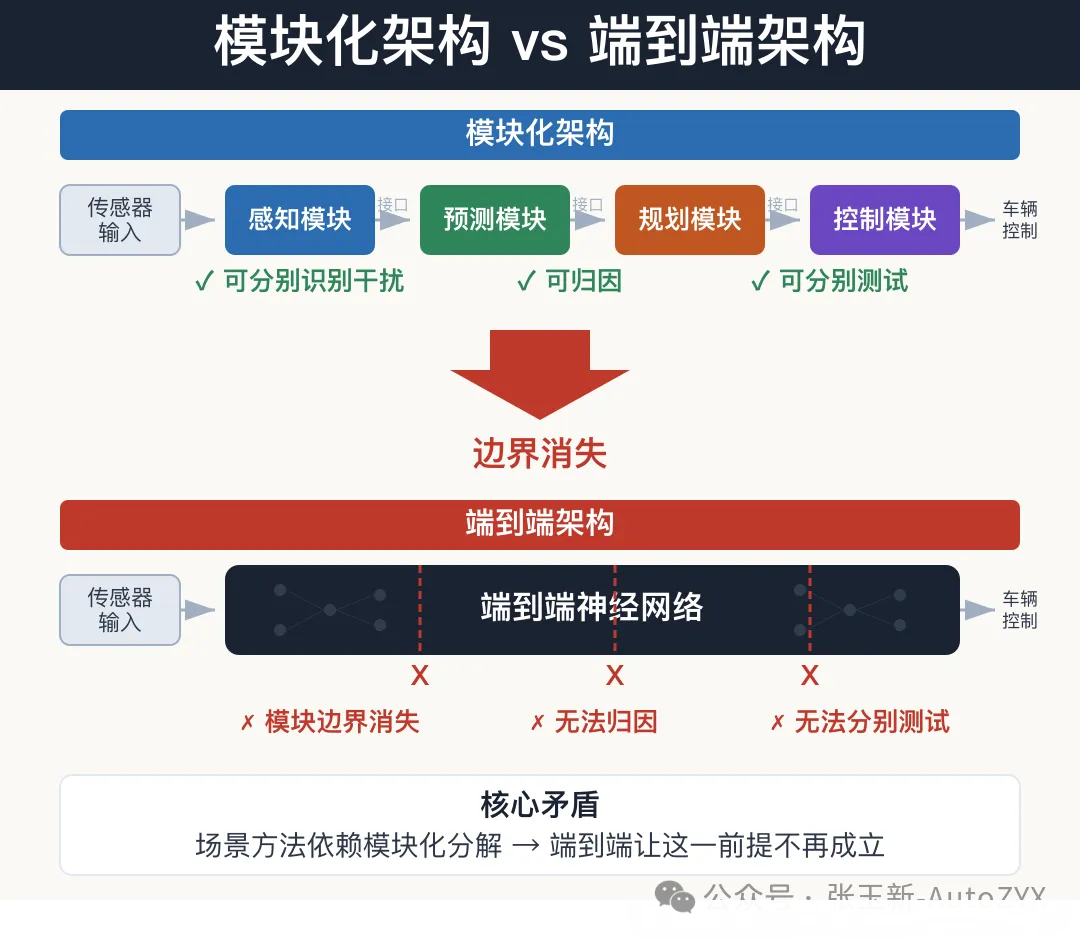
Figure 5
2.1 Module Boundaries Vanish: Disturbances Cannot Be Attributed
SAKURA’s entire methodology is built upon DDT three-process decomposition — perception disturbances, traffic disturbances, and dynamics disturbances are identified and tested separately.
But end-to-end architectures fuse perception, prediction, planning, and even control into a single neural network. Models like UniAD and DriveTransformer are characterized precisely by eliminating the explicit boundaries between intermediate modules.
This means that when the system fails in a given scenario, you cannot determine whether it “didn’t see it,” “saw it but misjudged,” or “judged correctly but failed to execute.” The clear “three categories of disturbance” in the SAKURA framework lose their corresponding observation points on an end-to-end system.
2.2 Causal Chains Break: Root Cause Analysis Becomes Intractable
In a modular architecture:
Collision → planning module output a wrong trajectory → because prediction module underestimated lead vehicle deceleration → root cause identified
In an end-to-end architecture:
Collision → neural network output a wrong control signal → ??? → cannot trace back to a specific failure mechanism
The behavior of end-to-end systems is emergent, not a modular causal chain. This poses a fundamental challenge to safety argumentation — when you cannot answer “why did it fail?”, how do you argue “it won’t fail again”?
2.3 Behavioral Non-Determinism: Same Scenario, Different Outputs
Traditional scenario testing assumes system behavior is deterministic: given the same input scenario, the system should produce the same output behavior.
However, diffusion-model-based end-to-end approaches (such as DiffusionDrive) are inherently probabilistic — running the same scenario multiple times may yield different trajectory plans. This forces a rethink of the conventional “scenario Pass/Fail” criterion: if it passes 9 out of 10 runs, is that a Pass or a Fail?
2.4 The Limitation of Pairwise Interactions: Real-World Complexity
This point is often overlooked, but it may be the most fundamental issue.
The 24 highway scenarios defined by ISO 34502 are fundamentally built around “ego vehicle + one opponent vehicle” pairwise interactions. Even with the “occluded target” in cut-out scenarios, the interaction is at most three-way.
But in the real world, a vehicle at any moment is typically interacting with 5 to 15 or more road users:
You are preparing to change lanes on the highway
A car behind you on the left is accelerating
A large truck ahead on the right is moving slowly
Two cars ahead are engaged in a lane-change contest
A broken-down vehicle sits on the emergency lane, with a person standing beside it
An oncoming vehicle just flashed its high beams
These are not six independent pairwise interactions, but a multi-agent coupled scenario. Each participant’s behavior is influenced by all the others, forming a complex interaction network.
End-to-end systems are built precisely to handle this complexity — they map directly from full-scene sensor input to driving decisions, without decomposing interactions into pairwise pairs.
Yet our testing frameworks still evaluate them using pairwise interactions.
Figure 5: Pairwise interaction vs. multi-agent scenario clusters
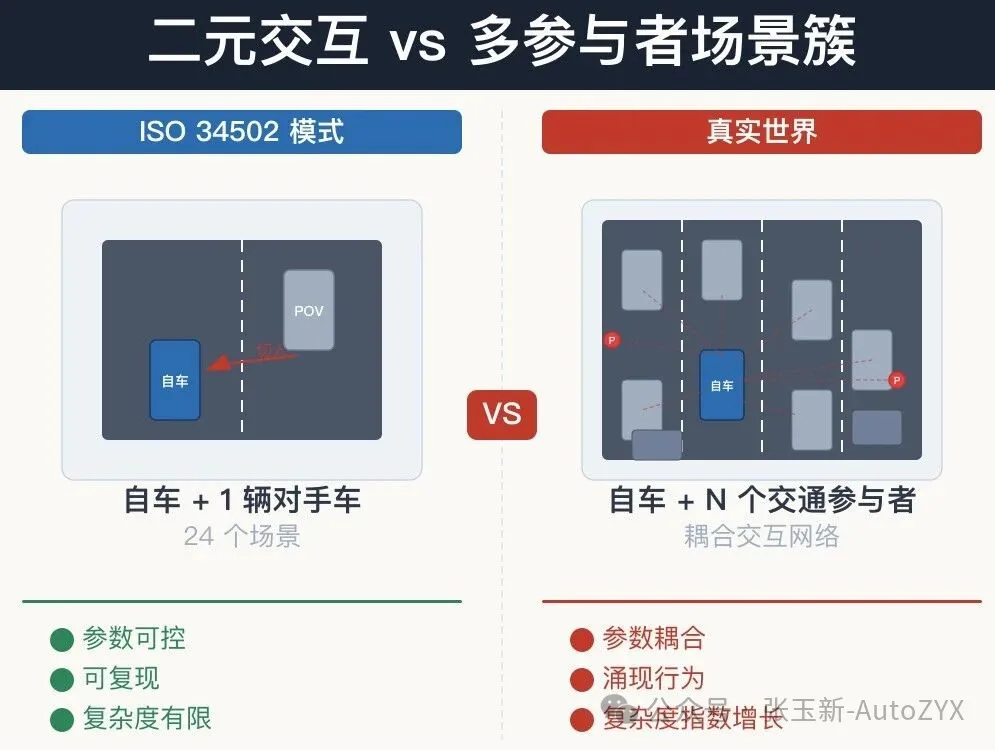
Figure 6
2.5 The Coverage Illusion: Quantity Does Not Equal Safety
This is the most profound and least discussed challenge.
Scenario enumeration is fundamentally sampling discrete points from a continuous state space. Even if you generate one million scenarios and pass all of them, you still cannot rule out a fatal failure at scenario number 1,000,001.
More critically, safety violations tend to occur near the structural boundaries of the parameter space — precisely the regions that standard scenario sets are most likely to miss.
“Having generated enough scenarios” is not the same as “the system is safe enough.” This is not a fault of the scenario method itself, but its capability boundary.
3. Scenario Methods Are Still Valid — But Need Supplementation
3.1 Why We Cannot Abandon Scenario Methods
The five challenges above do not mean scenario methods are obsolete. On the contrary, scenario methods provide value that no other approach can replace:
First, structured requirements definition. ISO 34502’s three-layer scenario model provides a systematic path from “vague safety requirements” to “testable, concrete use cases.” Whether the system architecture is modular or end-to-end, requirements definition needs this structure.
Second, actionable test design. The 58 traffic disturbance patterns + sensor disturbance models give simulation and real-vehicle testing a clear starting point. Without scenario methods, test engineers would have nowhere to begin.
Third, the foundation for regulations and standards. UN R157 (the world’s first L3 regulation), China’s mandatory L2 and ADS standards, ISO 21448 SOTIF — these regulations, either in force or imminent, are all built on scenario methods. They cannot be overturned in the short term.
Fourth, traceable safety argumentation. Every test case in the scenario method traces back to a specific safety requirement and a physical principle. This traceability is increasingly demanded by regulators.
So the right question is not “do we still need scenario methods?” but “what else do we need to add?”
3.2 The Value of Large-Scale Naturalistic Driving Data
The answer points in one direction: large-scale naturalistic driving data from the real world.
The value of this type of data is that it is not “designed” scenarios, but everything that naturally occurs in real traffic — including interaction patterns you would never think of, that no standard has defined, but that undeniably exist.
Specifically, large-scale naturalistic driving data can supplement scenario methods at three levels:
Level 1: Complete Coverage of Real Parameter Distributions for All Typical Scenarios
ISO 34502 defines 24 highway traffic disturbance scenarios; SAKURA V4.0 expands to 58 vehicle traffic patterns and 8 VRU patterns. Each scenario has a clearly parameterized definition — cut-in angle, relative speed, and lateral distance for cut-in scenarios; TTC and THW for car-following; merge angle and gap for merging scenarios, and so on.
Figure 6: SAKURA typical scenario definitions
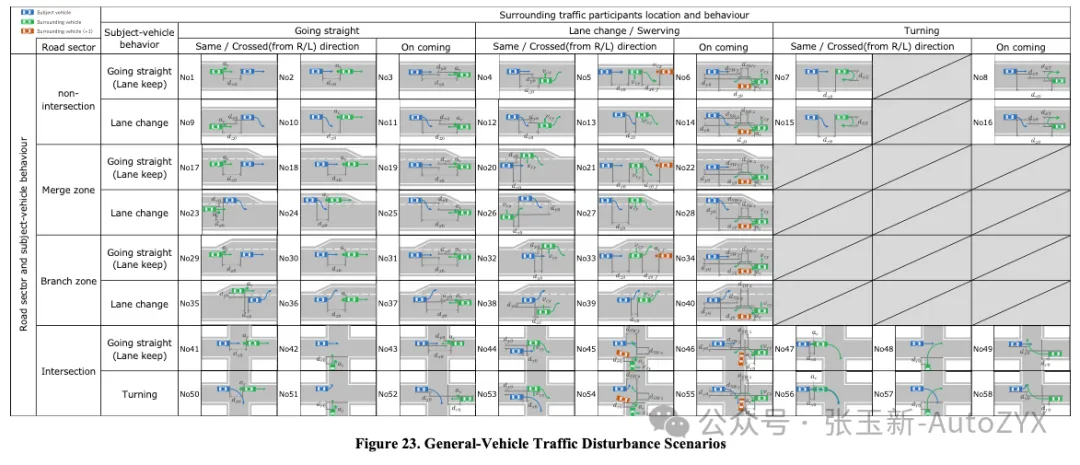
Figure 7
But the standards define the parameters — they do not provide the real-world distributions of those parameters on Chinese roads.
This is not an academic issue; it directly affects the daily work of OEMs and Tier 1 suppliers:
During requirements definition: when defining the ODD and performance metrics for intelligent driving functions, what is the “reasonably foreseeable” maximum speed differential in a cut-in scenario? What is the 5th percentile TTC in seconds? These numbers directly determine the quantified metrics in your functional specification. Using Japanese data to write requirements for a Chinese product is like calibrating parameters for Changchun using Tokyo traffic flows.
During test design: when building a simulation test matrix, how wide should the parameter value ranges be? If ranges are too narrow, you miss real-world edge cases; too wide, and you waste test resources on implausible combinations. Real distribution data lets you precisely delineate test boundaries, significantly improving test efficiency.
During safety argumentation: “reasonable foreseeability” is one of the most critical criteria in the SAKURA framework — you need to argue that “this parameter range covers X% of real-world situations.” Without localized parameter distribution data, that X% is impossible to calculate.
This is precisely where large-scale aerial naturalistic driving data delivers value: it can comprehensively extract all typical scenario types defined in ISO 34502 and SAKURA V4.0 — from highway cut-in/cut-out/deceleration/merge/diverge scenarios, to urban intersection conflicts/VRU interactions/occlusion scenarios — and provide the real parameter distributions for each scenario type, specific to the Chinese target market.
Figure 7: Extracting typical scenarios from aerial survey data
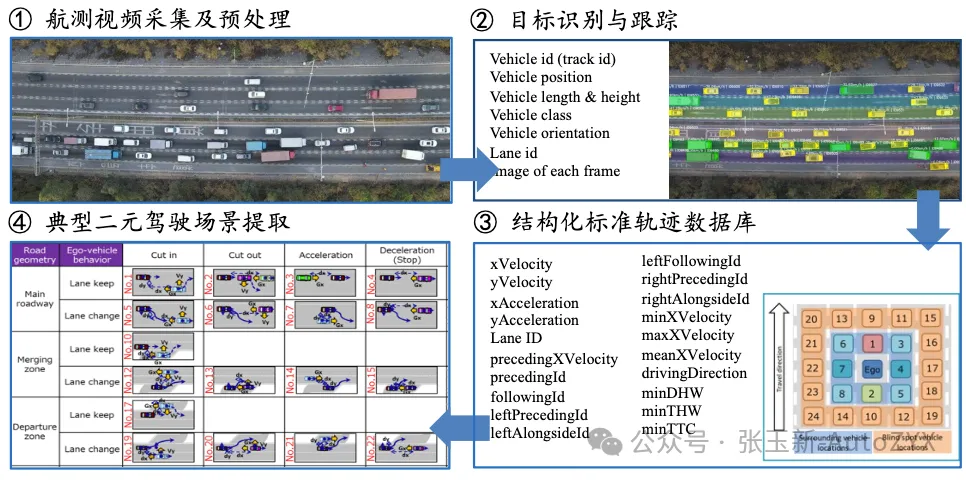
Figure 8
Existing research has shown that Chinese drivers’ behavioral parameters in cut-in scenarios differ significantly from those of European and Japanese drivers. Directly reusing parameters calibrated by SAKURA based on Japanese data is neither accurate nor safe for the Chinese market.
For OEMs and Tier 1 suppliers, this means: evidence-based quantitative metrics during requirements definition, real-boundary efficiency guarantees during test verification, and localized statistical support during safety argumentation.
Figure 8: Scenario parameter distribution comparison (China vs. Japan data)
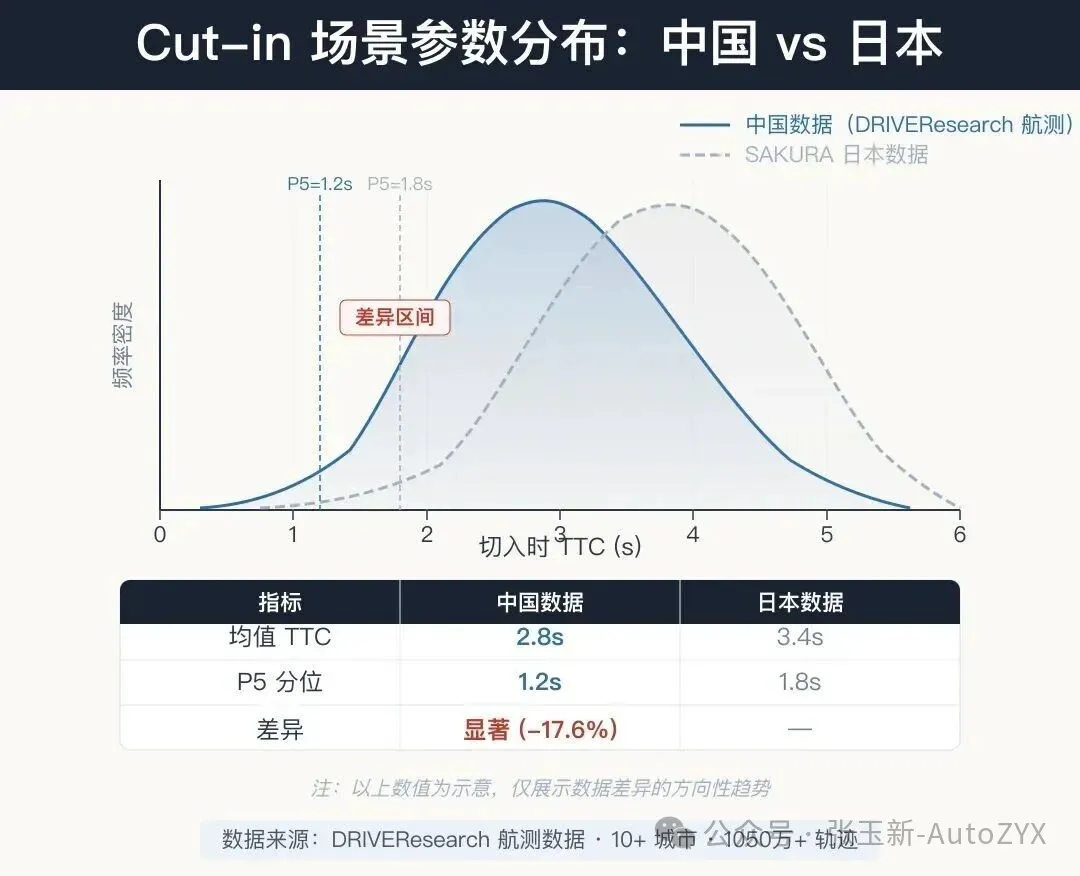
Figure 9
Level 2: Beyond Pairwise Interactions — Multi-Agent Scenarios
Traditional sensor-based perspectives (onboard cameras/radar/LiDAR) have an inherent limitation: they can only observe traffic participants within the ego vehicle’s sensor range. Occluded pedestrians, vehicles engaged in lane-change contests further ahead, vehicles outside the ego vehicle’s field of view but about to enter the interaction zone — all are blind spots.
Drone-based “bird’s-eye view” naturalistic driving datasets can simultaneously observe all participants across the entire traffic flow. This unlocks a critical capability:
Extracting “multi-agent scenario clusters” — not isolated pairwise interactions, but the coupled interaction network formed by all participants within the same spatiotemporal window.
For example, when you observe a highway merge zone from the bird’s-eye view, you see not “one car cutting in front of another,” but “five cars completing a series of interconnected accelerations, decelerations, lane changes, and yielding negotiations over 30 seconds.” This is the real input that end-to-end systems actually face.
Figure 9: Efficiently extracting multi-vehicle group interaction behavior from aerial survey data
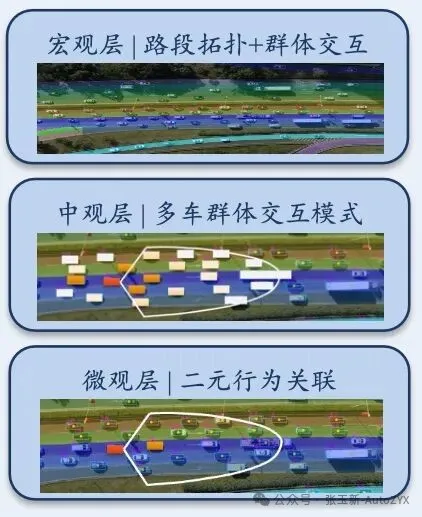
Figure 10
Level 3: The Data Foundation for a Driver Foundation Model (DFM)
SAKURA’s C&C Driver model uses “a reaction delay of 0.75 seconds + maximum deceleration of 0.774G” to define the safety benchmark. This is a deterministic binary model: meet it and you Pass; don’t and you Fail.
But a Driver Foundation Model (DFM) built on 10.5 million+ real driving trajectories can provide probabilistic, multi-dimensional behavioral benchmarks: for a given scenario, what is the safety margin distribution of the top 5% of drivers, the efficiency distribution, the comfort distribution?
This is not about replacing standards with data, but providing standards with a more robust data foundation.
3.3 The Unique Advantages of Aerial Survey Data
Why the emphasis on aerial (drone) data? Because it solves a core problem that onboard sensor data cannot:
Figure 10: Different data collection methods

Figure 11
The last point is particularly critical: when you observe the complete trajectories of all 10 vehicles in a scenario, any one of them can be designated as the “ego vehicle,” with the remaining 9 forming its interaction environment. A single data collection yields scenario data from 10 perspectives. For training and testing end-to-end systems, this data efficiency is N times that of onboard approaches.
4. The Way Forward: A Three-Layer Collaborative Framework
I believe that autonomous driving safety evaluation in the end-to-end era requires three layers of methods working in concert:
Layer 1: Structured scenario testing (ISO 34502 / SAKURA). Continues to serve its core role in requirements definition, test structuring, and regulatory compliance. The scenario classification system derived from physical principles will not become obsolete.
Layer 2: Data-driven behavioral benchmarks. Using large-scale naturalistic driving data to provide real distributions for scenario parameters, probabilistic benchmarks for safety criteria, and to compensate for the limitations of deterministic models. The key here is that the data must cover the ODD of the target market, rather than directly applying data from another country.
Figure 11: Typical commuting scenario driving cycle
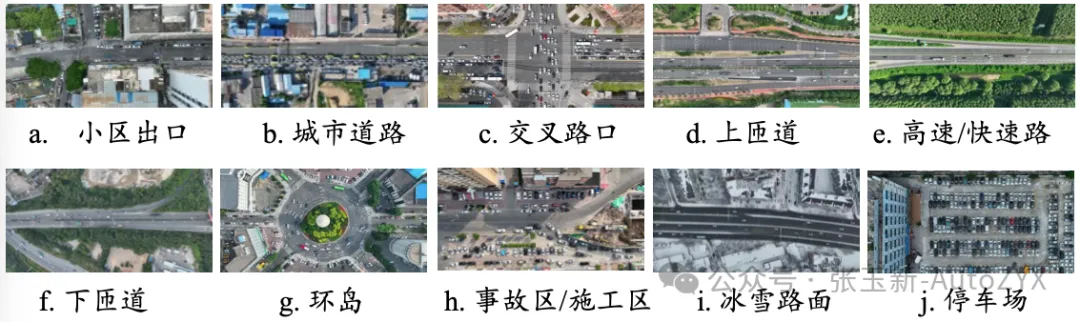
Figure 12
Layer 3: Structural guarantees from formal methods. Formal verification and reachability analysis answer the question “regardless of the scenario, what must never happen.” This does not depend on scenario enumeration, but provides safety guarantees at a structural level. In the face of the non-determinism of end-to-end systems, this layer is especially important.
Each of the three layers has its strengths and its limits. Scenario methods provide an actionable testing framework, data methods provide real-world statistical benchmarks, and formal methods provide structural safety guarantees.
Figure 13: Three-layer collaborative framework
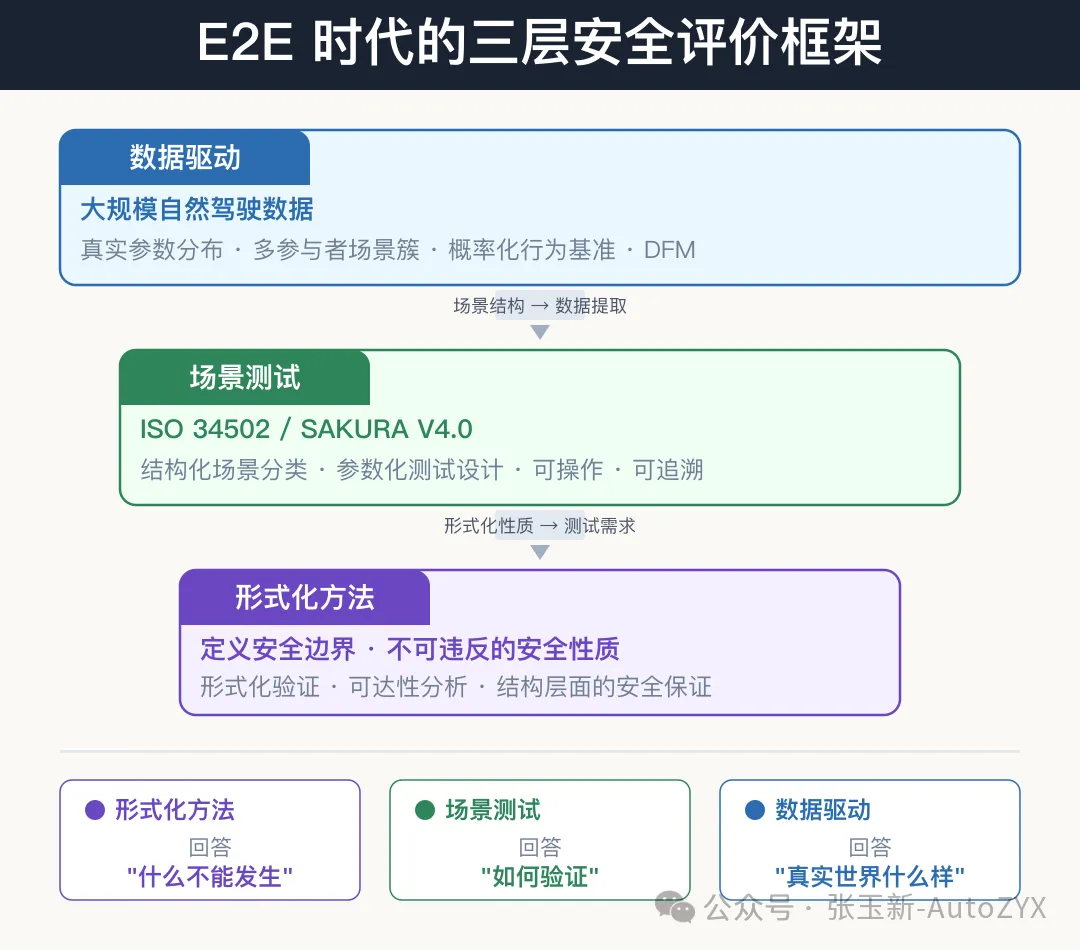
Figure 13
Within this framework, scenarios are no longer independent “evidence” of safety, but “witnesses” — passing scenarios witness consistency with safety properties; failing scenarios witness the existence of counterexamples.
5. Conclusion
Returning to the question in the title: in the end-to-end era, is scenario-based safety evaluation still valid?
Valid, but no longer sufficient.
ISO 34502 and SAKURA V4.0 have built the most rigorous scenario-driven safety evaluation system available today. Their methodology — the Physical Principles Approach, three-layer scenario abstraction, systematic disturbance identification — remains effective and irreplaceable in the end-to-end era.
But end-to-end architectures bring structural challenges: vanishing module boundaries, broken causal chains, behavioral non-determinism, and complex multi-agent interactions. Scenario methods need the supplement of large-scale real-world data.
In particular, bird’s-eye-view naturalistic driving datasets based on aerial surveys, with their unoccluded full-scene observation capability, can extract parameter distributions for all typical scenarios within the ISO 34502 framework — and more importantly, break through the limitation of pairwise interactions to capture the coupled interaction patterns of multiple traffic participants in the real world.
This shift from “designing scenarios” to “discovering scenarios” may be the pivotal step in the evolution of safety evaluation methodology for the end-to-end era.
References
[1] ISO 34502:2022 Road vehicles — Test scenarios for automated driving systems — Scenario based safety evaluation framework
[2] JAMA, Automated Driving Safety Evaluation Framework Ver. 4.0, 2026. https://www.jama.or.jp/english/reports/framework.html
[3] Zhang Y, Wang C, Shum H P H. Benchmarking Autonomous Vehicles: A Driver Foundation Model Framework. CARS@EDCC, 2026.
[4] Chen L et al. End-to-End Autonomous Driving: Challenges and Frontiers. IEEE TPAMI, 2024.
[5] Olleja P et al. Validation of Human Benchmark Models for Automated Driving System Approval. Accident Analysis & Prevention, 2025.
[6] Zhang Z. Beyond Scenarios: Why AI-Driven Scenario Testing Is Incomplete Without Formal Methods, https://blogs.zengjiezhang.com/?blogId=20260220, 2026.
[7] Krajewski R et al. The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways, 2018.
[8] SAKURA Project. https://www.sakura-prj.go.jp/project_info/