导读:智能驾驶要“像人一样开车”,前提是搞清楚人到底是怎么开的。本文从“类人驾驶”这个概念出发,讨论人类驾驶行为研究的五个落地方向、获取答案的四条路径,以及我们团队正在做的开源数据实践。全文约5000字。本文 2026 年 3 月底首发于微信公众号,2026 年 6 月收录入本站。
人类自古以来就热衷于研究自己的行为。
婴儿后半夜为什么突然哭醒?我有经验——大半是尿憋的。
两三岁的孩子为什么每天追着你问一百个“为什么”?
青春期为什么开始在意同学的看法胜过父母?
刚工作的年轻人为什么明知该早睡却总忍不住刷手机到凌晨?
人到中年为什么突然迷上了跑步、钓鱼或者自驾?
人老了,为什么总喜欢翻老照片、讲当年的故事?
每一种行为研究的背后,都有实际的用处。搞清楚孩子为什么问“为什么”,你就不会不耐烦而是顺势引导;理解了“报复性熬夜”的心理机制,你才能真正改掉它;知道中年人为什么迷上户外,也许下一个消费品牌就藏在里面。
那——人到底是怎么开车的?搞清楚这个问题,又能帮到谁?
一、研究“人类”驾驶,实现“类人”驾驶
我研究车辆相关的工作,不经意间也快二十年了,时间都去哪儿了!从小对车就非常感兴趣,小时候在农村,很少有漂亮的轿车从门口经过,每次都会和小伙伴追在车后面跑,连闻汽车尾气都觉得是一种乐趣。
高考的时候,每一个志愿填的第一专业都是车辆工程。本科没去成,进了机械工程。后来辗转进入吉大汽车学院读博,研究过水陆两栖车、工程车辆、飞行汽车、商用车……最终聚焦到乘用车智能驾驶方向。
近十几年的核心工作,是研究智能驾驶的安全——怎么让智能系统比人更安全。
在这个过程中,我逐渐意识到一个问题:要让系统“比人更安全、或高一个数量级”,你得先知道人的安全水平到底是什么样的。更进一步,要让智能驾驶“像人一样开车、开得比人更好”,得先搞清楚人到底是怎么开车的。
前几天卓驭×红旗的BOSS直测中,沈老师反复提到一个词——“类人驾驶”。我觉得这个词比行业里常说的“拟人驾驶”更好。“拟人”是“模拟人”,暗含着一个假设:人是标准答案,系统去模仿就好。但“类人”更诚实——它承认智能驾驶不是也不该是人类的复制品,而是一种“像人但可以更好”的驾驶方式。安全的底线要守住甚至超越,但在舒适、效率、交互节奏上,要像人一样自然。
更妙的是,“类人”和“人类”恰好构成一组镜像。我们研究的是“人类”的驾驶行为,研究的目的,是让智能驾驶实现“类人”的驾驶。
人类,类人。两个字颠倒过来只需要一秒,但从研究人类驾驶到实现类人驾驶,中间隔着海量的数据采集、场景分析、模型构建、工程验证——这条路很长也很艰辛,但值得整个行业去推进。

什么是“类人驾驶”?安全是底线,这毫无疑问。但消费者真正为之买单的,是那些比“安全”更微妙的东西:起步不顿、跟车不紧、变道不愣、过弯不晃。绿灯亮了不会傻等半天,遇到加塞不会急刹到乘客晕车。
这些不是靠几个安全指标就能覆盖的。这些是人类在日常驾驶中,每天都在做的事情。
驾驶行为研究其实由来已久。我的导师郭孔辉院士,早在1981年赴美国密歇根大学做访问学者期间,就在驾驶员行为模型与人-车闭环系统动力学仿真方面做出了开创性的工作。当时的驾驶员模型主要服务于车辆操纵稳定性研究,而非自动驾驶。

近年来更常被提及的是“驾驶员参考能力模型”,比如UNECE R157法规和ISO 34502中的定义,主要基于场地测试——在封闭环境中,选取驾驶员样本,针对特定场景进行测试,得出关键安全参数。这些工作很有价值,它们画出了安全的底线。
但场地测试能覆盖的场景是非常有限的。而人类每天在路上面对的场景,99%以上都不是那些极限工况。起步时踩油门的力度曲线,跟车时保持的时距随速度怎么变化,过弯时的轨迹偏好,在十字路口和行人、非机动车怎么交互——这些“正常”的行为数据,才是实现“类人驾驶”的真正基准。
场地测试画出“安全”的底线,自然驾驶数据画出“类人”的基准。两条线之间,就是智能驾驶该有的样子。

二、这个答案到底对谁有用
回到那个问题:搞清楚“人是怎么开车的”,到底能帮到谁?
我沿着一辆智能汽车从开发到上路的全过程来展开。

产品定义和系统开发
智能驾驶的开发链条上,很多环节都需要人类驾驶行为数据作为参考。
当前行业正在快速向端到端方案演进——感知、决策、控制不再是分开的模块,而是一个大模型端到端学习。但即便在端到端的范式下,仍然有大量工作离不开“人类是怎么开的”这个问题:
- 产品经理在定义功能边界:城市NOA需要覆盖哪些场景?这些场景中人类的行为多样性有多大?
- 系统/安全工程师在划定安全边界:巡航功能需要应对多激进的加塞?什么程度的cut-in算超出系统能力?
- 数据工程师在筛选训练数据:海量车端数据中,哪些片段包含高价值的人车交互行为?筛选标准是什么?
- 测试工程师在定义验收标准:端到端模型输出的轨迹,怎么判断“够好”还是“不够好”?
他们面对的其实是同一个问题:人类在这些场景下到底是怎么开的?
据我了解,现实中很多边界和标准是“拍脑袋”定的,或者从文献里找一个不太完备的数字凑合用。上路后发现太激进或太保守,再反复调。说实话,很多时候做了很多妥协。
如果有一份足够丰富的人类驾驶行为数据——不同速度段、不同道路类型、不同交互场景下的行为参数分布——上面这些工作就可以从“拍脑袋”变成“看数据”。
这不是效率的提升,是开发范式的升级。
标准制定与合规测试
标准法规是智能驾驶准入和上路的门槛。门槛定得太低,有安全隐患;定得太高,企业合规成本爆炸,技术进步被拖慢。
场地测试数据能支撑有限场景下的标准制定。但中国的交通环境——高速加塞、非机动车混行、不规则路口、匝道博弈——远比场地测试能模拟的要复杂得多。
更丰富多样的自然驾驶场景数据与实车场地测试等数据联合,可以在两个维度上帮助标准制定:
一是场景选择更合理。哪些场景在中国的道路上真正高频出现?哪些场景看似常见实则罕见?有了大规模自然驾驶数据的统计支撑,标准中纳入的场景就能更贴近真实道路情况,而不是靠专家经验或个别热点事件来决定。
二是通过阈值更准确。日本的SAKURA项目在这方面做了很好的方法论探索——它提出了“可预见/不可预见”和“可预防/不可预防”的四象限框架,给出了典型场景清单。但要画出每个具体场景中那条“可预防边界”到底在哪里——比如在某个速度段下,多短的TTC算“人类也来不及反应”,多长的TTC算“正常人完全可以避免”——这需要大量真实数据来定义,而不是拍脑袋划一条线。
类人驾驶测评
这是我认为当前最有价值、也最有想象力的应用方向。
现有的辅助驾驶和自动驾驶标准法规测试,大多聚焦在安全性上:能不能识别障碍物?能不能紧急制动?这些当然重要——车厂和供应商会使用“各种方法”让推向市场的量产车的智驾系统都能“通过”这类场景——但消费者的感受远不止于此。
经常看智驾博主试驾视频的朋友一定熟悉这些场景:
- 高速上开着智驾,旁边车道的车一个接一个插进来——系统每次都礼让,你坐在车里越来越焦虑,最后忍不住接管了。
- 前面明明没什么车了,智驾还在用60码的速度慢悠悠地巡航——你手动踩一脚油门,车速上去了,体验也上去了。
- 过一个大曲率弯道,方向盘修正的节奏和你自己开时不一样——说不上哪里不对,但你就是觉得不自然。
这些画面在各种直播和试驾评测中反复出现。有意思的是,博主们和车企领导在描述这些问题时,用的几乎都是主观感受——“跟车太远了”“过弯有点愣”“起步不够丝滑”。但到底“太远”是远了多少?“不够丝滑”的减速曲线长什么样?目前并没有一个权威的量化基准来回答这些问题。
这恰恰是“类人驾驶”真正要解决的事情。智能驾驶要想让消费者真正信任并愿意持续使用,不仅要“安全”,还要在舒适性和通行效率上接近甚至超越人类驾驶习惯——而这些维度的量化,必须建立在大规模人类驾驶行为数据之上。
类人驾驶测评需要的不是“一个老司机的意见”,而是“千万条行车轨迹告诉你的答案”。
事故研究:区分“能避免”和“避不了”
前面说的都是正向开发和测评的应用。还有一个是反向的——从事故中学习。
交通事故数据是极其宝贵的资源。但光看事故本身,你很难判断一个关键问题:这个事故,换一个正常的人类驾驶员,能不能避免?
举个例子。一辆车在高速上正常行驶,旁边静止的车突然起步切入你的车道——这种场景,再老的老司机也来不及反应。如果智能驾驶在这个场景中也没能避免碰撞,不应该因此被判定为不合格。
但另一种情况:前车明显在减速,跟车距离也足够,一个正常驾驶员完全可以从容制动——如果智能驾驶在这个场景中追尾了,那就是系统的问题。
怎么区分这两种情况?你需要一个参照:正常人类驾驶员在同样的场景中,通常是怎么做的。
这恰恰是大规模自然驾驶数据能提供的东西。它记录了成千上万的正常驾驶行为——在各种速度、各种车距、各种交互场景下,人类驾驶员实际的反应时间、制动力度、规避策略。有了这些数据,就可以为事故分析提供一把客观的标尺:这个场景在正常驾驶中是什么样的?事故中的行为偏离了正常基线多远?
坦白说,我们的航测数据以正常交通流为主,非常激进的极限驾驶行为并不多见。这意味着它不太适合直接去定义安全的绝对阈值。但它恰好能提供“正常人类驾驶基线”——和事故数据形成互补。
事故数据告诉你“发生了什么”,自然驾驶数据告诉你“正常情况下应该是什么样”。两者结合,才能判断一个事故到底是系统的问题还是场景本身的极限。
车端持续优化
最后一个应用,是把人类驾驶行为模型集成到车上,作为实时参照。
熟悉特斯拉的朋友可能知道“影子模式”——人在开车,系统在后台默默运行,找出“如果系统来开,会和人不一样的地方”,作为高价值数据回传,帮助系统迭代。
我们说的这个应用,思路恰好反过来:智能驾驶在开车,人类驾驶行为模型在后台做评判。过十字路口,起步节奏和人类基准偏差多少?过弯时的轨迹和人类偏好差多远?跟车距离在这个速度段是否符合人类习惯?应对前车制动时,减速曲线是否足够“丝滑”?
特斯拉的影子模式是“人当老师,系统当学生”。而人类驾驶行为模型的思路是“系统当司机,人类基准当考官”。两者互为镜像,都在回答同一个问题:系统和人之间还差多远?
有了这样的参照,自动驾驶和辅助驾驶的每一次OTA迭代,都有了一个清晰的优化方向——不是“我觉得更好了”,而是“数据告诉我更像人了”。
三、获取答案的四条路径
知道了这个答案的价值,下一个问题自然是:怎么获取这个答案?
据我了解,至少有四种途径,各有侧重。

第一种:从神经学和心理学入手。给驾驶员佩戴各种设备,测量脑电波、生理信号、眼动轨迹,在驾驶模拟器中还原各种场景,剖析人在驾驶时的心理和生理变化。我们学院的高振海老师、胡宏宇老师在这方面有深厚的研究基础,从人因的角度去探索智能驾驶系统带给人的安全感、舒适体验的规律,进而更好的去进行优化设计,这也是人车交互与协同的本质。这类研究通常基于典型样本试验产出机理性认知,而非大规模统计意义上的行为模型。
第二种:实车场地测试。在封闭场地中,选取不同性别、年龄、驾驶经验的驾驶员样本,针对特定场景反复测试,采集数据,提取关键参数。日本的SAKURA项目和UNECE R157法规中的驾驶员参考能力模型,主要就是这样得来的。功能安全领域的“可控性测试”也是同一思路。这条路径的优势是场景可控、数据精确,但覆盖的场景类型非常有限。
第三种:真实道路的跟车采集。在量产车上安装传感器,长期跟踪驾驶员在真实道路上的驾驶行为。同济大学牵头的China-FOT项目是国内的先行者,产生了大量有价值的研究成果。这条路径的优势是场景真实,但采集的是“车端视角”——只能看到本车驾驶员的行为和前方有限的交通情况。
第四种:路侧或无人机上帝视角采集。从灯杆或空中俯视视角,同时采集几十上百辆车的轨迹数据。人类怎么通过红绿灯,怎么和行人交互,怎么在匝道汇入车流,怎么在拥堵中加塞和被加塞,怎么在冰雪路面上谨慎驾驶——全都在一帧帧画面里。
这四种路径不是互相替代的关系。神经学解释“为什么”,场地测试定义“安全底线”,FOT采集“个体纵深”,上帝视角覆盖“群体全景”。它们共同拼出人类驾驶行为的完整画像。
而航测数据的独特价值在于它的高效率和广度。它采集的是日常交通中所有参与者的行为——不是一个驾驶员的深度数据,而是一千万条轨迹的统计规律。对于回答“人类在各种场景下到底是怎么开车的”这个问题,它可能是覆盖面最广、成本效率最高的途径。
一个绕不开的问题:端到端时代,这些上帝视角的数据还有用吗?
说到这里,有必要正面回应一个业内很多人心里的疑问。
当前智能驾驶的技术路线正在向数据驱动的端到端方案快速演进。这里的“数据驱动”中的数据,绝大多数是车端采集的数据——摄像头、激光雷达、毫米波雷达采集的海量感知数据。车端数据的量级已经非常庞大,把它们充分利用起来,当然是训练和提升端到端自动驾驶系统的核心手段。
这就引出一个自然的疑问:既然车端数据已经这么多了,基于航测的上帝视角的自然驾驶数据——缺少车端视角,只有俯视轨迹——还有必要吗?
我的看法是:车端数据回答的是“系统该怎么开车”,航测数据回答的是“人类是怎么开车的”。这是两个不同的问题。
车端数据训练的是系统的感知和决策能力——看到什么、怎么反应。而航测数据提供的是一个外部参照系——人类在同样的场景下,实际上是怎么做的。前者是让系统“能开”,后者是判断系统“开得像不像人”。
另一个挑战更现实:端到端模型趋向于黑箱,系统工程师或产品经理基于人类驾驶行为定义的那些阈值——比如跟车时距、起步延迟、过弯速度——怎么注入到一个端到端模型里?这不是一个简单地“写进规则”就能解决的问题。
但反过来想,正因为端到端模型越来越黑箱,从外部去评判它“像不像人”就变得更重要了。你没法打开黑箱看里面的参数对不对,但你可以看它的输出行为和人类基准之间的偏差。人类驾驶行为数据在这里扮演的角色,不是训练数据,而是评价基准。
端到端解决了“怎么开”的问题,但“开得好不好”的判断,终究需要一把来自人类的尺子。
四、我们在做什么,以及接下来打算做什么
我和团队过去几年一直在做的事情,就是沿着第四条路径往下走。
当前积累了700多个小时的航测数据,提取了1000多万条行为轨迹,覆盖高速公路、城市快速路、匝道、十字路口、环岛、冰雪路面等多种场景。采集地点覆盖长春、深圳、武汉、西安等10多个城市,并基于中国各地区、各城市的驾驶特色,选取新的采集地点进行数据拓展。
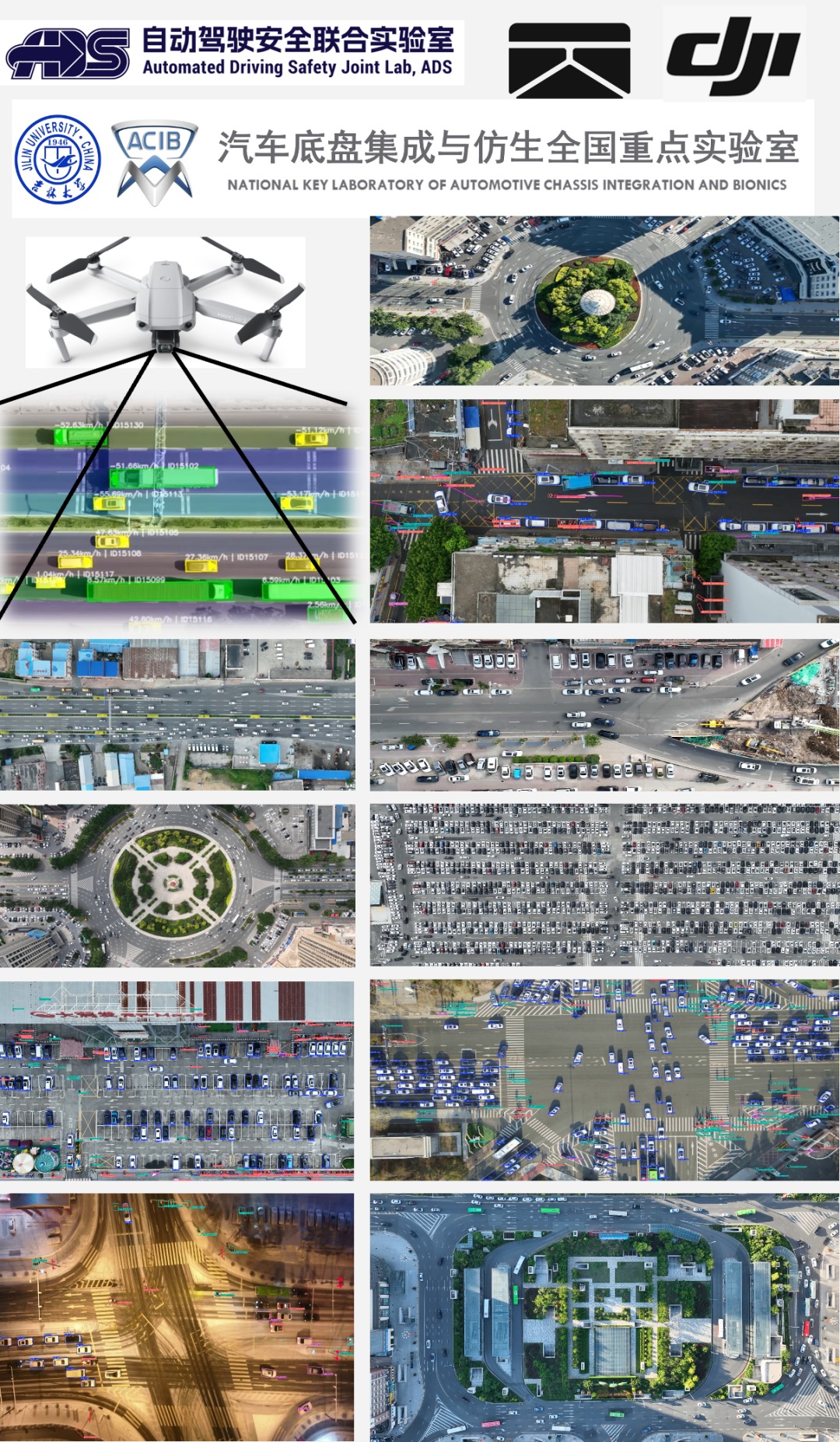
我们正在基于这些数据训练一个“中国驾驶员基础模型”——输入场景参数,输出人类驾驶员在该场景下的行为预测和参数分布。这件事艰难但有意义,因为它本质上是在把“人类是怎么开车的”这个问题的答案,从散落的数据变成一个可以被调用的模型。
在应用探索上,我们已经在和几个方向的合作伙伴一起推进:
- 和卓驭科技合作,基于航测数据提取高速公路和快速路上的危险场景指标(TTC、THW等),将轨迹数据集中的动态目标及静态地图转化为高逼真3DGS资产,在模拟器中进行端到端算法的仿真验证——这是航测数据从“看得见”到“用得上”的关键一步。
- 和泛亚汽车技术中心探索大规模自然驾驶数据在高级别自动驾驶系统预期功能安全正向开发中的应用——帮助开发工程师把“拍脑袋”变成“看数据”。
- 在学术层面,联合吉林大学、同济大学、瓦特大学、杜伦大学的研究者,基于大规模自然驾驶数据构建中国驾驶员基础模型——为智能驾驶的“类人化”提供安全感、舒适性、通行效率等多维度的人类行为基线。
- 和公安部道路交通安全研究中心探索自然驾驶基线数据与事故数据的互补——事故数据记录了“发生了什么”,自然驾驶数据提供“正常情况下应该是什么样”,两者结合才能判断一个事故场景是系统的问题还是场景本身的极限。
- 和德国亚琛fka研究所旗下的leveLXData团队开展数据合作。leveLXData是航测自然驾驶数据应用的先驱,他们在全球139个以上地点采集了400多小时的航测数据,覆盖欧洲、北美。我们和他们的合作,核心目的之一是进行中外驾驶行为的差异性分析。
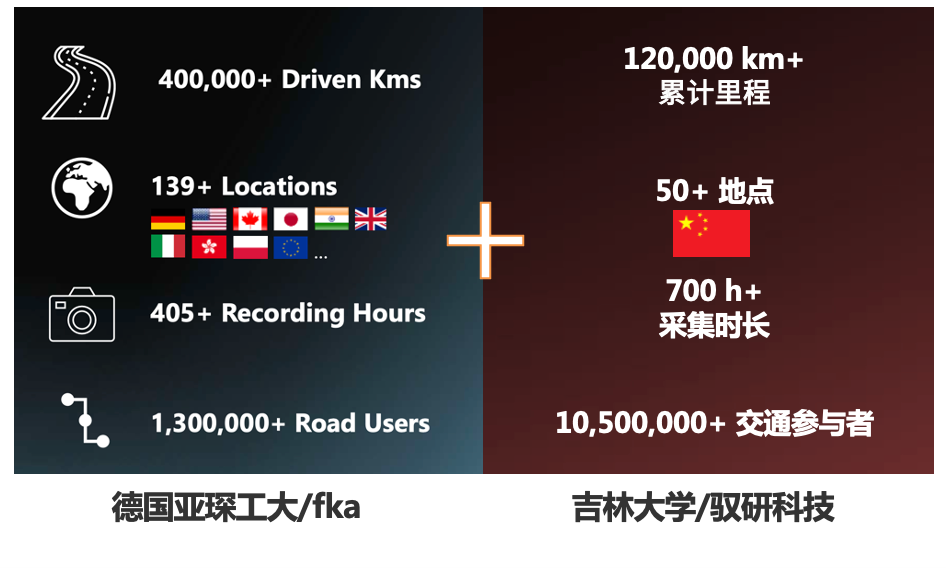
这里要特别说一点:研究“人类是怎么开车的”,必须从目标市场出发。不同国家和地区的驾驶员行为差异非常大——德国不限速高速公路上的跟车习惯、美国四路停(four-way stop)路口的交互礼让、中国的高频加塞和非机动车混行——这些不是“文化差异”这四个字能概括的,每一个差异背后都对应着不同的安全边界和类人基准。用德国的驾驶行为数据去评价中国的智能驾驶系统,或者反过来,都会得出错误的结论。这也是为什么我们坚持采集和研究中国本土的自然驾驶数据。
接下来我们要做的一件重要的事:开源更多典型场景的轨迹数据和参数分布。
开源典型场景下的样本数据和参数分布——比如高速公路跟车场景中,不同速度段下人类驾驶员的TTC分布和跟车时距分布。研究者可以直接用于算法验证和论文对标,工程师可以据此判断这类数据是否和自己的工作相关。
但由于每家企业的智能驾驶系统面对的运行设计域(ODD)不同,关注的功能场景不同,需要的参数维度和精度也不同。比如做城市NOA的企业和做高速HWP的企业,需要的场景类型完全不一样;做AEB标定的工程师和做端到端算法训练的工程师,关注的行为参数也不同。这些针对特定ODD、特定功能、特定指标的定制化分析,需要在完整数据集上进行深度挖掘——这是开源样本无法替代的。
我们希望通过开源降低整个行业使用自然驾驶数据的门槛。这个问题的答案太重要了,不应该完全锁在任何一家机构的硬盘里。先让更多人看到数据的价值,才会有更多人一起把答案做得更完整。
事实上,我们团队已经有一些开源实践:
AD4CHE(Aerial Dataset for China Congested Highway and Expressway):为满足大众中国Rush Hour Pilot项目需求(尤其是拥堵场景下的近距离加塞),我们与大疆车载(卓驭科技)合作开源了面向中国高速公路和快速路的拥堵场景航测数据集,目前已有国内外400多家机构申请使用。

SinD(Signalized Intersection Dataset):清华大学王红老师主导、我们协助的信号灯控制交叉口的航测数据集,覆盖完整的红绿灯周期下的多车交互和人车交互行为。

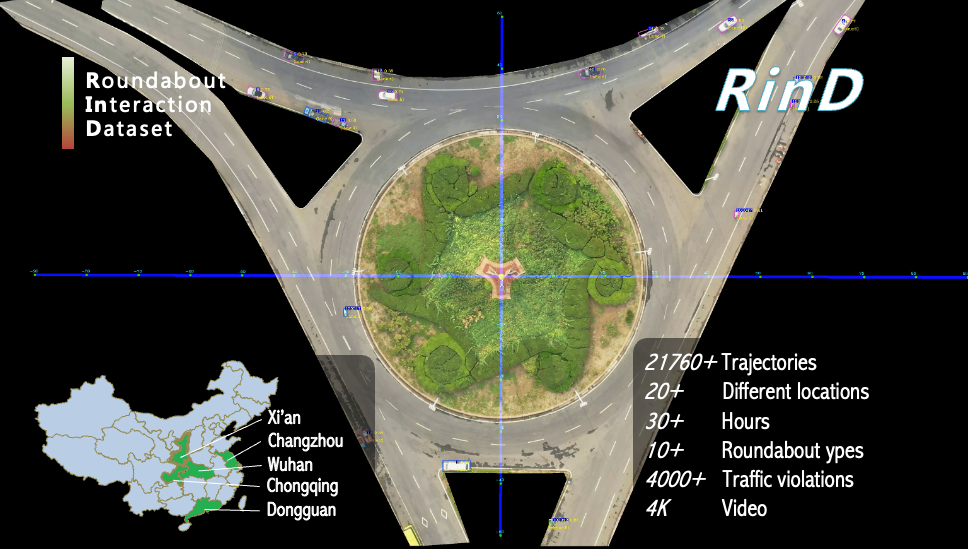
RinD(Roundabout Interaction Dataset):重庆大学李楚照老师主导、我们支持的复杂环岛交互航测数据集,重点关注复杂构型环岛场景下的人车交互行为。
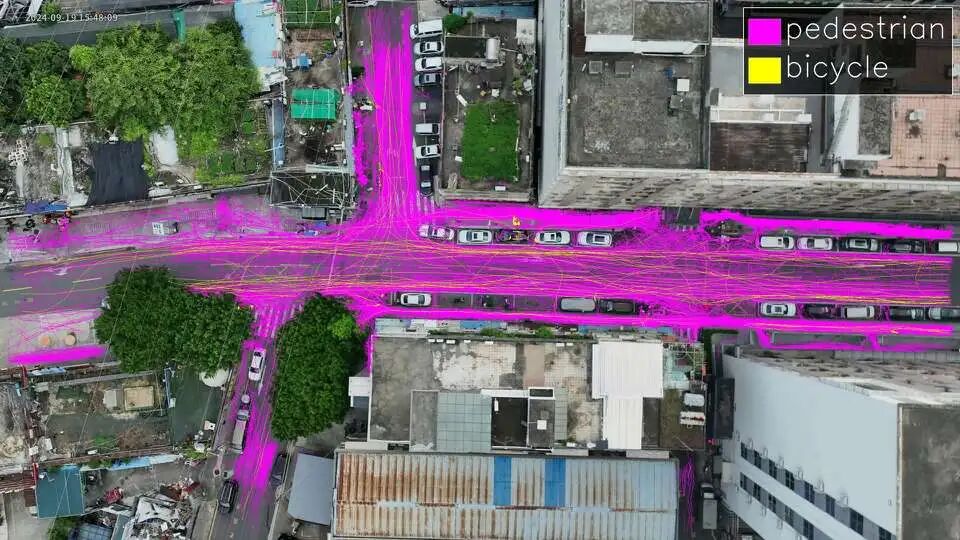
VRUD(Vulnerable Road User Dataset):专注于机动车与弱势交通参与者VRU(行人、非机动车)高度混行场景的航测数据集。
接下来计划开源的还有冰雪道路专题数据集——覆盖东北冬季冰雪路面的驾驶行为,研究人类驾驶员在附着力极低的路面上怎么跟车、怎么制动、怎么过弯,与相同路段正常条件下的驾驶行为有何差异。此外还有复杂环岛、典型施工区、事故多发区等更多专题数据集正在规划中。
每一次开源,都是在把“人类到底是怎么开车的”这个问题的答案的一个切面,分享给整个行业。
尾声
写到这里,回头看看开头那些关于人类行为的研究。
研究小孩的行为是为了让父母更轻松。研究择偶是为了找到对的人。研究人是怎么开车的,是为了让每一辆智能汽车更懂什么是“好好开车”。
研究“人类”驾驶行为,实现“类人”智能驾驶。这条路很长,但方向很清楚。
不过话说回来,研究人是怎么开车的,我自己倒也不是纸上谈兵。十几年驾龄,开着房车(&数据采集车)从长春到深圳再到云南,又从深圳回长春、进内蒙,从黑龙江到北京……中国几个来回跑下来,也亲身经历了不少特殊路况。在北美和欧洲的十来个国家的老城区和山间小道上,和当地司机“博弈”过——每次都在想,不同国家的驾驶员面对同样的弯道、同样的加塞,行为模式到底有什么不同?这大概就是职业病吧,开着车也在研究人是怎么开车的。
但我越开越相信一件事:一个好司机和一个好的智能驾驶系统,本质上需要同样的东西——对路况的理解,对风险的预判,以及对车内外每一个人的尊重。
这条路,我们会持续走下去。
历史文章
未来的更多数据开源,请关注驭研科技 DRIVEResearch:driveresearch.tech